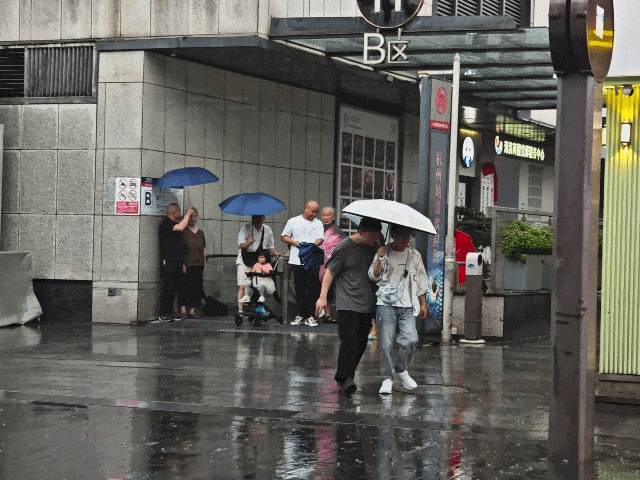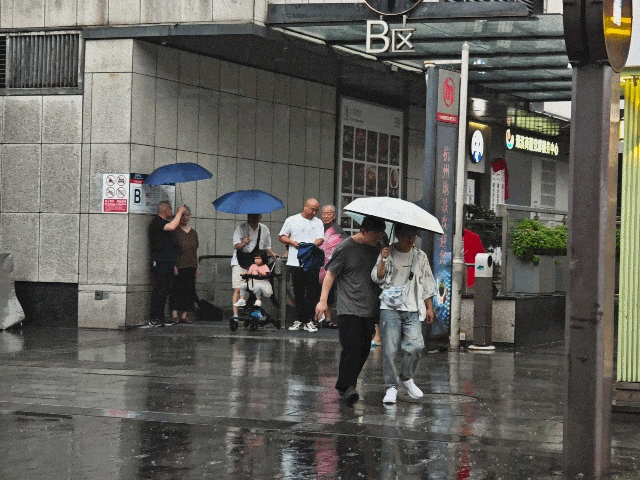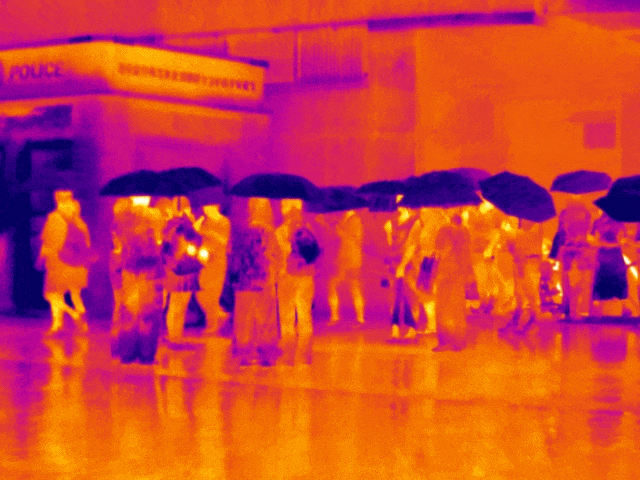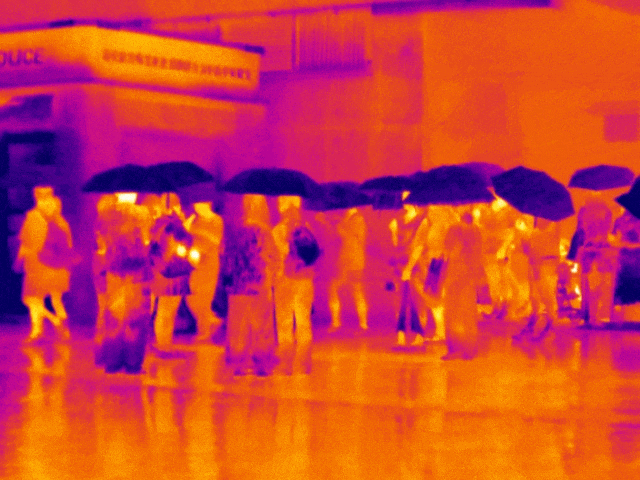在自動駕駛中,環境感知是一個非常重要的環節,它不僅可以幫助無人駕駛汽車進行定位,還可以告知障礙物等信息以幫助決策模塊去調整駕駛行為。在視覺感知任務中,實際上有很多細分的任務類型,比如目標檢測、目標跟蹤、語義分割、實例分割、關鍵點檢測等,而這些細分任務在我們的環境感知中都有著非常重要的應用。
1、關鍵點檢測技術簡介
在圖像處理中,關鍵點本質上是一種特征。它是對一個固定區域或者空間物理關系的抽象描述,描述的是一定鄰域范圍內的組合或上下文關系。它不僅僅是一個點信息,或代表一個位置,更代表著上下文與周圍鄰域的組合關系。

比如在人臉關鍵點檢測任務當中,有 28 個關鍵點,或是現在比較流行的 64 個、128 個關鍵點,這里面每個點在不同的人臉當中,代表了一類的特征,且具有一定的通用性。這一類特征不僅包含了像素的一些特性,比如嘴唇的特征點,包含了嘴唇與面部的位置關系。
右邊的圖片是前段時間比較火的阿里推出的服飾關鍵點比賽,比如在這件服飾中提供了 13 類關鍵點,每個關鍵點之所以被定位為一類關鍵點,因為它代表了服飾當中某一個特定的位置,或者某一個特定的位置所能代表的周圍的關系。而在人體姿態檢測當中,這個關鍵點不僅代表一個關節,還代表著這個關節和其他關節之間的關系,比如這個關節能跟其他哪些關節聯系得比較緊密。
2、關鍵點檢測在自動駕駛中的應用
在自動駕駛當中,有一些關鍵點檢測的應用。

比如箭頭的檢測,檢出箭頭的同時,可以把它的關鍵節點回歸出來,不同的顏色的點代表不同的類型,并且不同的點有它的位置信息。通過這些點,作為地圖上的坐標,可以實時、精確地告訴車輛,告訴自動駕駛的大腦,我們現在的位置。箭頭的關鍵點檢測,也是用了類似的方法,雖然它的網絡模型已經改得面目全非了,但是它的原理是一樣的,通過不同等級的金字塔級別,可以把不同級別的點信息融合起來,從而提高它的精度,另一方面提高它的檢測率。

在箭頭或者是其他的一些關鍵點當中,也是需要知道每個點和另外一個點之間連接的關系,也就是它關系的回歸。

并不是所有的點回歸都能夠很精確。比如有些點在圖像上,車輛運行過程中,有些箭頭的關鍵點可以準確地回歸出來,有些可能識別出來錯誤,這受限于我們之前學習到的經驗等。這類問題可以通過一些后續的改進,比如說網絡的改進、攝像本身的改進。另外也可以通過后期的其他公式、其他算法上用的多一幀或是匹配的方式,去修正一下錯誤。

另外在自動泊車或者自主泊車當中,需要先檢測出車位,我們用點回歸的方式可以把車位的頂點回歸出來。在一個圖象當中,可以回歸出車位當中的一些關鍵點,這個關鍵點是有不同類型的。通過車位的關鍵點,我們可以精確獲知到我們實車或者是車輛自身距離這些關鍵點和車位之間距離是多少,我們相對的要調整控制模塊,使得我們能夠自動泊進去這個車位。所以,回歸的車位頂點信息,對我們自動泊車或者是自主泊車來說是非常重要的信息。
另外,利用點回歸的方式,同時結合語義分割的手段,可以給出一個信息更加豐富的結果,網絡可以輸出這方面的結果,相當于是分割出來的車位信息、車庫當中車輛數的信息、車位是不是空車位、這個區域是不是空車位的信息。

同時通過點回歸的方式,在網絡的另一個分支,可以得到關鍵點的位置在哪里。比如我們知道這個地方是個空車位,我們也知道它車位的位置,這樣對我們自動泊車來說,就可以直接去停,這是很好的感知功能。

除此之外,在室外的一些定位當中,可以用關鍵點回歸的方法去回歸路牌的定點。可以通過這個點反饋在地圖上,更加精確地知道我們實時的位置。對路牌來說,2D 目標檢測并不能全面描述其信息,因為圖像中有很多傾斜的路牌。通過點回歸的方式,可以清晰地得到它在圖像中的真實形狀與位置。通過一些攝像機的成像原理,或其他的修正手段,可以把這個位置信息投影到真實的三維信息當中去,更好地幫助我們確定車輛自身在三維世界當中的位置。
在圖象當中做二維 bounding box 之或做三維bounding box 的目標檢測,點和點之間的關系后剩下的頂點其實就可以看做是關鍵點,去掉的這個關系就是它的框,也就是它的連接關系。所以,去掉連線之后,就可以看成一個點回歸的問題。做目標檢測或者是做三維目標檢測當中,比較重要的研究問題是如何把這個點回歸的問題做得更精確。有很多人用一些模板的方式,比如說像目前百度的 Apollo 2.5 當中,其實有一個模式是相當于把這邊真實的三維的候選做了很多匹配,看哪個跟檢測出來的更相近或者更相匹。
這個方法,其他公司也有類似的狀況,在做點回歸的時候,都是直接在圖片當中做三維的點回歸,因為二維的點回歸是比較相似的。我們可以看到在比較遠處時候,就直接二維回歸,在稍微近一點的時候,可以做三維的點回歸。因為在遠處的時候,這個側面是很難看出來的,在相對比較近的時候,可以精確地描述。目標車輛下面這個斜邊代表著它的航向角,這個航向角和公共的航向角定義不太一樣,相當于這個車身的航向角,這個航向角對我們來說很主要的,可以判斷出或者是輔助我們判斷出前方車輛運動的趨勢或者是運動的范圍。
因為結合多幀信息,這個航向角會有變化的曲線,我們根據這個曲線可以預測出這個車輛是否有變道,或者是否有急轉這樣的趨勢。通過這樣的信息,可以幫助決策模塊做一些重要的決策。比如預測出前方車輛要變道插隊了,防插隊也是我們自動駕駛當中遇到的很重要的問題;比如很多車,做 L1 和 L2 的方案當中,在嘗試編程當中,前方車輛如果要插隊,對我們自動駕駛的車輛來說很難識別。前面的車有沒有插隊的趨勢,一般都是是有一定經驗的司機能夠準確或者是最高精度地判斷出來。因為是否能夠判斷出前方車輛司機有插隊趨勢,對于我們正常的人類司機來說,也造成了很多的事故。因為判斷不出來前面的車輛是否有插隊的趨勢,而前面的很多新手司機突然變道,這樣就會發生一些比較經典的擦碰或者是追尾事故。這類事故放在自動駕駛車輛上來說,理論上可以做到比人類更高的精度。
用點回歸的方式,可以去解決在一些場景當中三維目標檢測的問題。對于點回歸來說,需要根據周圍的關系去判斷這個點是不是應該在這里。而在三維檢測的時候,經常會出現目標不全或者是目標存在一定遮擋的問題,這就需要我們去增加它的感受范圍,或者是增強它在這方面的處理能力,這是可以去有效規避的事情。
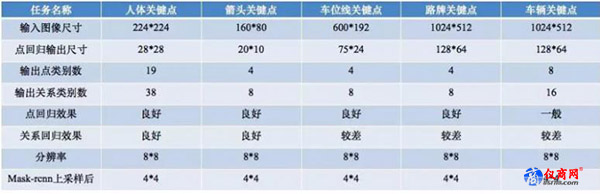
可以用一些小的網絡去做,比如說這張表當中描述的是用不同的方法去回歸點不同的任務,如人體、箭頭、車位線、路牌、車輛等,還有很多其他類型的點回歸任務,都可以用這種方法,總體上來說,都是可以去解決,但是處理的能力是有限的。比如在車輛的關鍵點上來說,車輛的關鍵點回歸的時候,整體回歸的效果一般,因為車輛本身也是一個比較難的問題,整體的精度也比 2D 的要低很多。目前精度比較高的方法仍然是以激光雷達數據為輔助的方法,以視覺為主的方法目前還沒有打進前三名,甚至只能排前十。
另外一方面,在用經典的 mask-rcnn 方法去做這類問題的時候,也受限于剛才所說的精度問題,下采樣的倍數越高,回歸得到的結果精度就越難以保證。這方面用到了很多級聯的方法來提高精度,比如先用一個 28 x 28 的,再用 56 x 56 的,再用一個 112 x 112 的,這樣精度逐漸提高了,但是它的運算量并沒有被提高,或者復雜度并沒有被提高,不是乘的關系而是加的關系,用兩者的策略做的事情。這在我們的算法工程師或者是同行業當中,應該不是什么難的問題。