在機器人和計算機視覺領域,光學 3D 距離傳感器已經得到了廣泛應用,比如 RGB-D 攝像頭和 LIDAR 傳感器,都在 3D 環境繪制和無人駕駛等任務中扮演了重要角色。
盡管它們性能十分強大,兼具高敏感度、高精度和高可靠性等特質,但在識別透明物體上卻不盡如人意。想要破壞這些傳感器的成像效果,或者讓機械手臂無從下手,只需要在它們面前放上玻璃杯一類的透明物體就可以了,因此難以在不使用其他傳感器的情況下獨立完成特定任務。
這是因為光學傳感器的算法假設所有表面均是理想散射的 (Lambert),即物體會在各個方向和各個角度均勻地反射光線。在 Lambert 光照模型中,無論觀察者的視角如何,其表面亮度都是相同的。
現實中的絕大多數物體符合這一假設,除了透明物體,因為它們的表面既折射又反射光線。這樣一來,光線傳播的復雜性大幅提升,表面亮度與視角無關的假設被破壞了,基于 Lambert 模型的算法也就失效了,導致傳感器收集的透明物體的大多數深度數據都是噪聲或者無效的。

圖 | 透明物體在傳統算法眼中是噪聲(來源:谷歌 AI)
為了改善這一問題,讓機器可以更好地感知透明表面,谷歌 AI,Synthesis AI 和哥倫比亞大學的研究人員合作開發了一種名為 ClearGrasp 的機器學習算法,能夠從 RGB-D 圖像中估算透明物體的準確 3D 數據。
根據谷歌 AI 介紹,在設計之初,ClearGrasp 算法就考慮到了兼容性。它可以與任何標準 RGB-D 相機捕捉的數據配合使用,借助神經網絡和深度學習來準確地重建透明物體的景深數據。

圖 | ClearGrasp 算法的工作原理(來源:谷歌 AI)
與目前所使用的技術不同,ClearGrasp 算法不依賴于對透明物體的先驗知識,比如預先對透明物體進行 3D 建模,還要補充觀察視角和光線數據。在神經網絡的幫助下,它可以很好地泛化到從未見過的全新物體身上。
在測試過程中,研究人員將新算法集成到了一套現有的拾取機器人控制系統中,最終發現它對透明塑料物體的抓取成功率有了非常顯著的提升,最多可以提升 6 倍。未來有望在拾取機器人和自動駕駛等領域應用。
透明對象的可視數據集
無論是什么樣的深度學習模型,訓練時都要依賴于大量數據,比如訓練自然語言模型 BERT 需要維基百科,ClearGrasp 也不例外。然而目前廣泛使用的 3D 數據集,包括 Matterport3D 和 ScanNet,都會忽略透明表面和物體,因為標記過程過于復雜和耗時。
這讓研究人員不得不自己創建訓練集和測試集,專門針對透明對象設計。
在訓練數據集中,他們創造了 5 萬多個符合真實物理原則的渲染圖,每張圖片最多包含 5 個透明物體,放置于平面上或者開放式容器中,視角、背景和光線各不相同。每個物體還有配套的表面法線(曲率)、分割蒙版、邊緣和深度等信息,用于訓練各種 2D 和 3D 物體檢測任務。
至于測試集,研究團隊選擇用真實場景創建圖片和數據,方便最大程度上測試算法的真實表現。這是一個十分痛苦的過程,因為對于每個場景都要在保證視角、光線和場景布置完全一致的情況下照兩遍:第一遍用透明物體,第二遍用一模一樣的非透明物體替換它們(必須保證位置完全一樣)。

圖 | 布置真實場景(來源:谷歌 AI)
最終他們得到了 286 個真實場景測試圖,其中不僅包括透明物體本身,還有各種不同的背景貼圖和隨機不透明物體。圖片中既包含訓練集中存在的已知對象,也包括從未出現過的新物體。
在數據集的問題解決之后,下一步是思考如何收集透明物體的深度數據。
雖然在透明物體上,RGB-D 經典的深度估算方法無法給出準確數據,但仍然有一些蛛絲馬跡暗示了物體的形狀。最重要的一點是,透明表面會出現鏡面反射,在光線充足的環境中會顯示成亮點,在 RGB 圖像中非常明顯,而且主要受到物體形狀的影響。
因此,卷積神經網絡可以利用這些反射數據推斷出準確的表面法線,然后將其用于深度估算。
另一方面,大多數機器學習算法都嘗試直接從單眼 RGB 圖像中估計深度,不過即使對于人類而言,這也是一個困難的任務。尤其在背景表面比較平滑時,現有算法對深度的估計會出現很大的誤差。這也會進一步加大透明物體深度的估算誤差。
基于此,研究人員認為與其直接估算透明物體深度,不如矯正 RGB-D 相機的初始深度估算數據。這樣更容易實現,還可以通過非透明表面的深度來推算透明表面的深度。
ClearGrasp 算法
ClearGrasp 算法使用了三個神經網絡:一個用于估計表面法線,一個用于分析受遮擋邊界(深度不連續),另一個給透明對象罩上蒙版。蒙版負責刪除透明對象的所有像素,以便填充上正確的深度數據。
研究人員使用了一種全局優化模塊,可以預測表面法線并利用其來引導形狀的重建,實現對已知表面深度的拓展,還可以利用推算出的遮擋邊界來保持不同物體之間的分離狀態。
由于研究人員創建的數據集存在局限性,比如訓練圖片只包含放在地平面上的透明物體,因此初期的ClearGrasp 算法判斷墻壁等其他表面法線的表現很差。為了改善這一問題,他們在表面法線估算訓練中加入了 Matterport3D 和 ScanNet 數據集中的真實室內場景,雖然沒有透明物體,但針對真實場景的訓練有效提高了算法估算表面法線的準確率。
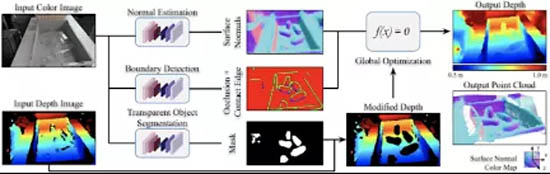
圖 | 三套神經網絡各有不同分工(來源:谷歌 AI)
為了系統分析 ClearGrasp 的性能,研究人員分別利用 RGB-D 數據和 ClearGrasp 數據構造了 3D 點云。點云顯示了算法所生成的 3D 表面形狀干凈且連貫,沒有原始單眼深度估算法中常見的鋸齒狀噪聲,而且還可以分辨復雜圖案背景下的透明物體,以及區分相互遮擋的透明物體。
最重要的是,ClearGrasp 輸出深度數據可以直接控制依賴于 RGB-D 圖像的機械臂。
研究人員使用了 UR5 工業機械臂進行測試,將其原始傳感器數據替換成 ClearGrasp 輸出深度數據后,它的透明物體抓取成功率得到了顯著改善:平行夾爪的成功率從 12% 大幅提升到 74%,吸爪的成功率從 64% 提升到 86%。

圖 | UR5 機械臂拾取透明物體(來源:谷歌 AI)
雖然分辨透明物體的準確率已經有了大幅提升,但新算法仍然有很大的進步空間。
研究人員認為,受到訓練數據集和傳統路徑跟蹤及渲染算法的局限性影響,ClearGrasp 仍然不能準確分辨散焦線,經常會把明亮的散焦線和物體陰影混淆為獨立的透明物體。這將是未來的重要研究方向之一。
研究人員相信,這項研究成果證明了,基于深度學習的深度數據重建方法足以勝過傳統方法,使機器能夠更好地感知透明表面,不僅有望提高 LIDAR 無人駕駛等技術的安全性,而且還可以在多變的應用場景中開啟新的交互方式,讓分類機器人或者室內導航等技術更加高效和可靠。